list: http://mohu.org/info/symbols/symbols.htm
handwritten symbol recognition: http://detexify.kirelabs.org/classify.html
Category: Tricks
【Tricks】Hello World!
之前见过这货的低配版
也是全部define成_,然后搞
但今天看到这货,用了define能组合的特点
真的是变态啊_(:з」∠)_
#define _________ }
#define ________ putchar
#define _______ main
#define _(a) ________(a);
#define ______ _______(){
#define __ ______ _(0x48)_(0x65)_(0x6C)_(0x6C)
#define ___ _(0x6F)_(0x2C)_(0x20)_(0x77)_(0x6F)
#define ____ _(0x72)_(0x6C)_(0x64)_(0x21)
#define _____ __ ___ ____ _________
#include<stdio.h>
_____
【日常小测】回转寿司
相关链接
题目传送门:http://oi.cyo.ng/wp-content/uploads/2017/07/20170623_statement.pdf
解题报告
看到这题我们不难想到分块
更进一步,对于每一个块来说,块内的数的相对大小不变
于是我们只需要用堆便可维护块内有哪些数
再稍加观察,我们发现只要再用一个堆记录块内的操作,然后从左向右扫一遍便可更新具体的数
于是我们就可以在:$O(n^{1.5} \log n)$的时间复杂度内解决这个问题了
另外priority_queue的构造函数是$O(n)$的
Code
#include<bits/stdc++.h>
#define LL long long
using namespace std;
const int N = 400009;
const int M = 25009;
const int S = 1000;
const int B = N / S + 10;
int n, sn, m, arr[N];
priority_queue<int> val[B];
vector<int> opr[B];
inline int read() {
char c = getchar();
int ret = 0, f = 1;
while (c < '0' || c > '9') {
f = c == '-'? -1: 1;
c = getchar();
}
while ('0' <= c && c <= '9') {
ret = ret * 10 + c - '0';
c = getchar();
}
return ret * f;
}
inline void get_element(int w) {
if (opr[w].empty()) {
return;
}
priority_queue<int, vector<int>, greater<int> > heap(opr[w].begin(), opr[w].end());
for (int i = max(1, w * S), lim = min((w + 1) * S - 1, n); i <= lim; i++) {
if (arr[i] > heap.top()) {
heap.push(arr[i]);
arr[i] = heap.top();
heap.pop();
}
}
opr[w].clear();
}
inline int modify_element(int w, int s, int t, int v) {
get_element(w);
int tmp = -1;
for (int i = s; i <= t; i++) {
if (v < arr[i]) {
tmp = arr[i];
swap(v, arr[i]);
}
}
val[w] = priority_queue<int>(arr + max(1, w * S), arr + 1 + min(n, (w + 1) * S - 1));
return v;
}
inline int modify_block(int w, int v) {
val[w].push(v);
int ret = val[w].top();
val[w].pop();
if (v != ret) {
opr[w].push_back(v);
}
return ret;
}
inline int solve(int s, int t, int v) {
int ss = s / S, st = t / S;
v = modify_element(ss, s, min(t, (ss + 1) * S - 1), v);
if (ss != st) {
for (int i = ss + 1; i < st; i++) {
v = modify_block(i, v);
}
v = modify_element(st, st * S, t, v);
}
return v;
}
int main() {
n = read(); m = read();
sn = n / S;
for (int i = 1; i <= n; i++) {
arr[i] = read();
}
for (int i = 0; i <= sn; i++) {
val[i] = priority_queue<int>(arr + max(1, i * S), arr + 1 + min(n, (i + 1) * S - 1));
}
for (int tt = 1; tt <= m; tt++) {
int s = read(), t = read(), v = read();
if (s <= t) {
v = solve(s, t, v);
} else {
v = solve(s, n, v);
v = solve(1, t, v);
}
printf("%d\n", v);
}
return 0;
}
【日常小测】异或与区间加
相关链接
题目传送门:http://oi.cyo.ng/wp-content/uploads/2017/06/claris_contest_4_day2-statements.pdf
官方题解:http://oi.cyo.ng/wp-content/uploads/2017/06/claris_contest_4_day2-solutions.pdf
解题报告
这题又是一道多算法互补的题目
通过分类处理使复杂度达到$O((n+m)\sqrt{n})$
具体来讲是将以下两个算法结合:
1. 枚举右端点的值,若左端点的合法位置超过$\sqrt{n}$个
考虑每一个左右端点应该加减多少,使用前缀和技巧将复杂度优化到$O(n + m)$
具体细节不想写了,有点麻烦_(:з」∠)_
然后因为合法位置超过了$\sqrt{n}$个,所以这种情况至多出现$\sqrt{n}$个,复杂度符合要求2. 其他情况
因为左端点不超过$\sqrt{n}$个,所以可以排序之后依次处理
使用分块来维护左端点的值,单次修改是$\sqrt{n}$的,单次查询是$O(1)$的
Code
#include<bits/stdc++.h>
#define LL long long
#define UI unsigned int
using namespace std;
const int N = 150009;
const int MOD = 1073741824;
const int blk_sz = 800;
int n, m, k, a[N];
UI a1[N], ans[N], blk_tag[N], tag[N];
vector<int> num, pos_list[N];
vector<pair<int, int> > left_list[N], right_list[N];
struct Query{
int l, r, w;
inline bool operator < (const Query &QQQ) const {
return r > QQQ.r;
}
}q[N];
inline int read() {
char c = getchar();
int ret = 0, f = 1;
while (c < '0' || c > '9') {
f = c == '-'? -1: 1;
c = getchar();
}
while ('0' <= c && c <= '9') {
ret = ret * 10 + c - '0';
c = getchar();
}
return ret * f;
}
inline int find(int x) {
int l = 0, r = num.size() - 1, mid;
while (l <= r) {
mid = l + r >> 1;
if (num[mid] == x) {
return mid;
} else if (num[mid] < x) {
l = mid + 1;
} else {
r = mid - 1;
}
}
return -1;
}
inline void solve(int A, int B) {
static UI a2[N], cur;
memset(a2, 0, sizeof(a2));
for (int i = 1; i <= n; i++) {
a2[i] = a2[i - 1] + (a[i] == num[B]);
}
cur = 0;
for (int i = n; i; i--) {
if (a[i] == num[B]) {
cur += a1[i];
}
if (a[i - 1] == num[A]) {
ans[i] += cur;
}
for (int j = 0; j < (int)left_list[i].size(); ++j) {
cur -= (UI)left_list[i][j].second * (a2[left_list[i][j].first] - a2[i - 1]);
}
}
memset(a2, 0, sizeof(a2));
for (int i = 1; i <= n; ++i) {
a2[i] = a2[i - 1] + (a[i - 1] == num[A]);
}
cur = 0;
for (int i = 1; i <= n; i++) {
if (a[i - 1] == num[A]) {
cur -= a1[i];
}
if (a[i] == num[B]) {
ans[i + 1] += cur;
}
for (int j = 0; j < (int)right_list[i].size(); ++j) {
cur += (UI)right_list[i][j].second * (a2[i] - a2[right_list[i][j].first - 1]);
}
}
}
int main() {
freopen("xor.in", "r", stdin);
freopen("xor.out", "w", stdout);
n = read(); m = read(); k = read();
num.push_back(0);
for (int i = 1; i <= n; ++i) {
a[i] = a[i - 1] ^ read();
num.push_back(a[i]);
}
sort(num.begin(), num.end());
num.resize(unique(num.begin(), num.end()) - num.begin());
for (int i = 0; i <= n; i++) {
int pp = find(a[i]);
pos_list[pp].push_back(i);
}
for (int i = 1, l, r, w; i <= m; ++i) {
l = q[i].l = read();
r = q[i].r = read();
w = q[i].w = read();
left_list[l].push_back(make_pair(r, w));
right_list[r].push_back(make_pair(l, w));
a1[l] += w;
a1[r + 1] -= w;
}
sort(q + 1, q + 1 + m);
for (int i = 1; i <= n; ++i) {
a1[i] += a1[i - 1];
}
for (int i = 0; i < (int)num.size(); i++) {
int r = i, l = find(num[i] ^ k);
if (l != -1 && (int)pos_list[l].size() > blk_sz) {
solve(l, r);
}
}
for (int r = n, cur = 0; r; r--) {
while (cur < m && q[cur + 1].r >= r) {
++cur;
for (int i = q[cur].l, lim = min(q[cur].r, (q[cur].l / blk_sz + 1) * blk_sz - 1); i <= lim; ++i) {
tag[i] += q[cur].w;
}
for (int i = q[cur].l / blk_sz + 1, lim = q[cur].r / blk_sz - 1; i <= lim; ++i) {
blk_tag[i] += q[cur].w;
}
for (int i = max(q[cur].r / blk_sz, q[cur].l / blk_sz + 1) * blk_sz; i <= q[cur].r; ++i) {
tag[i] += q[cur].w;
}
}
int t = find(a[r] ^ k);
if (t != -1 && (int)pos_list[t].size() <= blk_sz) {
for (int tt = 0; tt < (int)pos_list[t].size(); ++tt) {
int l = pos_list[t][tt] + 1;
if (l <= r) {
ans[l] += tag[l] + blk_tag[l / blk_sz];
ans[r + 1] -= tag[l] + blk_tag[l / blk_sz];
} else {
break;
}
}
}
}
for (int i = 1; i <= n; i++) {
ans[i] += ans[i - 1];
printf("%d ", ans[i] % MOD);
}
return 0;
}
【日常小测】友好城市
相关链接
题目传送门:http://oi.cyo.ng/wp-content/uploads/2017/06/claris_contest_4_day2-statements.pdf
官方题解:http://oi.cyo.ng/wp-content/uploads/2017/06/claris_contest_4_day2-solutions.pdf
解题报告
这题的前置知识是把求$SCC$优化到$O(\frac{n^2}{32})$
具体来说,就是使用$bitset$配合$Kosaraju$算法
有了这个技能以后,我们配合$ST$表来实现提取一个区间的边的操作
这样的话,总的时间复杂度是:$O(\frac{(\sqrt{m} \log m + q) n^2}{32}+q \sqrt{m})$
然后我懒,没有用$ST$表,用的莫队,时间复杂度是$O(\frac{(m + q) n^2}{32}+q \sqrt{m})$
调一调块大小,勉勉强强卡过去了
Code
#include<bits/stdc++.h>
#define LL long long
#define UI unsigned int
#define lowbit(x) ((x)&-(x))
using namespace std;
const int N = 159;
const int M = 300009;
const int QQ = 50009;
const int BlockSize = 1200;
const UI ALL = (1ll << 32) - 1;
int n, m, q, U[M], V[M], ans[QQ];
struct Query{
int l, r, blk, id;
inline bool operator < (const Query &Q) const {
return blk < Q.blk || (blk == Q.blk && r < Q.r);
}
}qy[QQ];
struct Bitset{
UI v[5];
inline void flip(int x) {
v[x >> 5] ^= 1 << (x & 31);
}
inline void set(int x) {
v[x >> 5] |= 1 << (x & 31);
}
inline void reset() {
memset(v, 0, sizeof(v));
}
inline bool operator [](int x) {
return v[x >> 5] & (1 << (x & 31));
}
}g[N], rg[N], PreG[M / BlockSize + 9][N], PreRG[M / BlockSize + 9][N];
inline int read() {
char c = getchar();
int ret = 0, f = 1;
while (c < '0' || c > '9') {
f = c == '-'? -1: 1;
c = getchar();
}
while ('0' <= c && c <= '9') {
ret = ret * 10 + c - '0';
c = getchar();
}
return ret * f;
}
inline void AddEdge(int u, int v, Bitset *a1, Bitset *a2) {
a1[u].set(v);
a2[v].set(u);
}
class Kosaraju{
vector<int> que;
Bitset vis;
public:
inline int solve() {
vis.reset();
que.clear();
for (int i = 1; i <= n; ++i) {
if (!vis[i]) {
dfs0(i);
}
}
vis.reset();
int ret = 0;
for (int j = n - 1; ~j; j--) {
int i = que[j];
if (!vis[i]) {
int cnt = dfs1(i);
ret += cnt * (cnt - 1) / 2;
}
}
return ret;
}
private:
inline void dfs0(int w) {
vis.flip(w);
for (int i = 0; i < 5; i++) {
for (UI j = g[w].v[i] & (ALL ^ vis.v[i]); j; j ^= lowbit(j)) {
int t = (__builtin_ffs(j) - 1) | (i << 5);
if (!vis[t]) {
dfs0(t);
}
}
}
que.push_back(w);
}
inline int dfs1(int w) {
vis.flip(w);
int ret = 1;
for (int i = 0; i < 5; i++) {
for (UI j = rg[w].v[i] & (ALL ^ vis.v[i]); j; j ^= lowbit(j)) {
int t = (__builtin_ffs(j) - 1) | (i << 5);
if (!vis[t]) {
ret += dfs1(t);
}
}
}
return ret;
}
}scc;
int main() {
freopen("friend.in", "r", stdin);
freopen("friend.out", "w", stdout);
n = read(); m = read(); q = read();
for (int i = 1; i <= m; i++) {
U[i] = read();
V[i] = read();
AddEdge(U[i], V[i], PreG[i / BlockSize], PreRG[i / BlockSize]);
}
for (int i = 1; i <= q; i++) {
qy[i].l = read();
qy[i].r = read();
qy[i].blk = qy[i].l / BlockSize;
qy[i].id = i;
}
sort(qy + 1, qy + 1 + q);
Bitset CurG[N], CurRG[N];
for (int i = 1, L = 1, R = 0; i <= q; i++) {
if (qy[i].blk != qy[i - 1].blk || i == 1) {
L = qy[i].blk + 1;
R = L - 1;
for (int j = 1; j <= n; j++) {
CurG[j].reset();
CurRG[j].reset();
}
}
if (qy[i].r / BlockSize - 1 > R) {
for (int j = R + 1, lim = qy[i].r / BlockSize - 1; j <= lim; j++) {
for (int k = 1; k <= n; k++) {
for (int h = 0; h < 5; h++) {
CurG[k].v[h] ^= PreG[j][k].v[h];
CurRG[k].v[h] ^= PreRG[j][k].v[h];
}
}
}
R = qy[i].r / BlockSize - 1;
}
if (L <= R) {
for (int i = 1; i <= n; i++) {
g[i] = CurG[i];
rg[i] = CurRG[i];
}
for (int l = qy[i].l; l < L * BlockSize; l++) {
AddEdge(U[l], V[l], g, rg);
}
for (int r = (R + 1) * BlockSize; r <= qy[i].r; r++) {
AddEdge(U[r], V[r], g, rg);
}
ans[qy[i].id] = scc.solve();
} else {
for (int i = 1; i <= n; i++) {
g[i].reset();
rg[i].reset();
}
for (int j = qy[i].l; j <= qy[i].r; ++j) {
AddEdge(U[j], V[j], g, rg);
}
ans[qy[i].id] = scc.solve();
}
}
for (int i = 1; i <= q; i++) {
printf("%d\n", ans[i]);
}
return 0;
}
【BZOJ 3577】玩手机
相关链接
题目传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=3577
神犇题解:http://www.cnblogs.com/clrs97/p/4403242.html
解题报告
之前一直都是线段树优化建图
这题需要用$ST$表来优化建图
Code
#include<bits/stdc++.h>
#define LL long long
using namespace std;
const int INF = 1e9;
const int N = 500000;
const int M = 2000000;
int S,T,E,tot,A,B,Y,X,n2[2][70][70][8];
int head[N],nxt[M],to[M],flow[M],n1[2][70][70];
inline int read() {
char c=getchar(); int f=1,ret=0;
while (c<'0'||c>'9') {if(c=='-')f=-1;c=getchar();}
while (c<='9'&&c>='0') {ret=ret*10+c-'0';c=getchar();}
return ret * f;
}
inline void AddEdge(int u, int v, int f) {
assert(u); assert(v);
to[++E] = v; nxt[E] = head[u]; head[u] = E; flow[E] = f;
to[++E] = u; nxt[E] = head[v]; head[v] = E; flow[E] = 0;
}
class NetworkFlow{
int dis[N],cur[N];
queue<int> que;
public:
inline int MaxFlow() {
int ret = 0;
while (BFS()) {
memcpy(cur, head, sizeof(cur));
ret += DFS(S, INF);
}
return ret;
}
private:
inline bool BFS() {
memset(dis, 60, sizeof(dis));
dis[S] = 0;
for (que.push(S); !que.empty(); que.pop()) {
int w = que.front();
for (int i = head[w]; i; i = nxt[i]) {
if (flow[i] && dis[to[i]] > INF) {
dis[to[i]] = dis[w] + 1;
que.push(to[i]);
}
}
}
return dis[T] <= INF;
}
inline int DFS(int w, int f) {
if (w == T) {
return f;
} else {
int ret = 0;
for (int &i = cur[w]; i; i = nxt[i]) {
if (flow[i] && dis[to[i]] == dis[w] + 1) {
int tmp = DFS(to[i], min(f, flow[i]));
ret += tmp; f -= tmp;
flow[i] -= tmp; flow[i ^ 1] += tmp;
if (!f) {
break;
}
}
}
return ret;
}
}
}Dinic;
int main() {
#ifdef DBG
freopen("11input.in", "r", stdin);
#endif
X = read(); Y = read();
A = read(); B = read();
S = ++tot; T = ++tot;
E = 1;
for (int i = 1; i <= X; ++i) {
for (int j = 1; j <= Y; ++j) {
n1[0][i][j] = ++tot;
n1[1][i][j] = ++tot;
AddEdge(n1[0][i][j], n1[1][i][j], read());
}
}
for (int i = X; i; --i) {
for (int j = Y; j; --j) {
for (int a = 0, len = 1; i + len - 1 <= X && j + len - 1 <= Y; ++a, len <<= 1) {
n2[0][i][j][a] = ++tot;
n2[1][i][j][a] = ++tot;
if (!a) {
AddEdge(n2[0][i][j][a], n1[0][i][j], INF);
AddEdge(n1[1][i][j], n2[1][i][j][a], INF);
} else {
int llen = len >> 1;
AddEdge(n2[0][i][j][a], n2[0][i][j][a - 1], INF);
AddEdge(n2[0][i][j][a], n2[0][i + llen][j][a - 1], INF);
AddEdge(n2[0][i][j][a], n2[0][i][j + llen][a - 1], INF);
AddEdge(n2[0][i][j][a], n2[0][i + llen][j + llen][a - 1], INF);
AddEdge(n2[1][i][j][a - 1], n2[1][i][j][a], INF);
AddEdge(n2[1][i][j + llen][a - 1], n2[1][i][j][a], INF);
AddEdge(n2[1][i + llen][j][a - 1], n2[1][i][j][a], INF);
AddEdge(n2[1][i + llen][j + llen][a - 1], n2[1][i][j][a], INF);
}
}
}
}
for (int i = 1, w, x1, x2, y1, y2, p0, p1; i <= A; ++i) {
p0 = ++tot; p1 = ++tot;
w = read();
x1 = read(); y1 = read();
x2 = read(); y2 = read();
AddEdge(S, p0, INF);
AddEdge(p0, p1, w);
int len = x2 - x1 + 1, lg = 0, d = 1;
for (; (d << 1) <= len; lg++, d <<= 1);
AddEdge(p1, n2[0][x1][y1][lg], INF);
AddEdge(p1, n2[0][x1][y2 - d + 1][lg], INF);
AddEdge(p1, n2[0][x2 - d + 1][y1][lg], INF);
AddEdge(p1, n2[0][x2 - d + 1][y2 - d + 1][lg], INF);
}
for (int i = 1, w, x1, x2, y1, y2, p0, p1; i <= B; ++i) {
p0 = ++tot; p1 = ++tot;
w = read();
x1 = read(); y1 = read();
x2 = read(); y2 = read();
AddEdge(p0, p1, w);
AddEdge(p1, T, INF);
int len = x2 - x1 + 1, lg = 0, d = 1;
for (; (d << 1) <= len; lg++, d <<= 1);
AddEdge(n2[1][x1][y1][lg], p0, INF);
AddEdge(n2[1][x1][y2 - d + 1][lg], p0, INF);
AddEdge(n2[1][x2 - d + 1][y1][lg], p0, INF);
AddEdge(n2[1][x2 - d + 1][y2 - d + 1][lg], p0, INF);
}
assert(tot < N);
assert(E < M);
printf("%d\n", Dinic.MaxFlow());
return 0;
}
【Tricks】Gedit的配置与计算器
Part 1. Gedit的配置
在拓展工具里创建新工具Complie
#!/bin/sh
fullname=$GEDIT_CURRENT_DOCUMENT_NAME
name=`echo $fullname | cut -d. -f1`
suffix=`echo $fullname | cut -d. -f2`
g++ $fullname -o $name
在拓展工具里创建新工具Run
#!/bin/sh
fullname=$GEDIT_CURRENT_DOCUMENT_NAME
name=`echo $fullname | cut -d. -f1`
suffix=`echo $fullname | cut -d. -f2`
dir=$GEDIT_CURRENT_DOCUMENT_DIR
gnome-terminal --working-directory=$dir -x bash -c "$dir/$name; echo; echo 'press ENTER to continue'; read"
Part 2. 计算器
NOI Linux下似乎没有图形界面的计算器
于是只能在终端中输入bc来使用命令行计算器
话说这货还挺好用的,唯一的问题就是:默认所有数全部为整数
我们需要使用scale=x来指定精度,x可以是任意自然数
—————————— UPD 2017.5.15 ——————————
被$Menci$啪啪啪 QwQ
请在终端中输入$xcalc$,有惊喜
—————————— UPD 2017.6.13 ——————————
学Python了,弃疗xcalc
【TopCoder SRM713】CoinsQuery
相关链接
题目传送门:https://community.topcoder.com/stat?c=problem_statement&pm=14572&rd=16882
题目大意
给$n(n \le 100)$类物品,第$i$类物品重量为$w_i(w_i \le 100)$,价值为$v_i(v_i \le 10^9)$,数量无限
给定$m(m \le 100)$个询问,第$i$询问请你回答总重量恰好为$q_i(q_i \le 10^9)$的物品,价值和最大为多少
你还需要求出使价值最大的方案数是多少(同类物品视作一样,摆放顺序不同算不同)
解题报告
规定每个物品重量不超过$100$那么我们就可以矩乘
但有一个问题:我们不仅要让价值最大,还要求方案数
但类比倍增Floyd:在一定条件,矩乘重载运算符之后仍然满足结合律
比如说这个题,我们可以:
重载加法为:两种方案取最优
重载乘法为:将两种方案拼起来(方案数相乘,价值相加)
然后直接做是$O(m n^3 \log n)$的,会在第$21$个点$TLE$
于是我们预处理转移矩阵的幂次,然后对于每个询问就是向量与矩阵相乘,单次复杂度是$O(n^2)$的
于是总的时间复杂度优化到:$O(m n^2 \log n + n^3 \log n)$
Code
#include<bits/stdc++.h>
#define LL long long
using namespace std;
const int MOD = 1000000007;
const int N = 101;
struct Data{
LL val,chs;
inline Data() {val = chs = -1;}
inline Data(LL a, LL b):val(a),chs(b) {}
inline Data operator + (const Data &D) {
if (chs == -1 || D.chs == -1) {
return chs != -1? *this: D;
} else {
Data ret(max(val, D.val), 0);
(ret.chs += (val == ret.val? chs: 0)) %= MOD;
(ret.chs += (D.val == ret.val? D.chs: 0)) %= MOD;
return ret;
}
}
inline Data operator * (const Data &D) {
if (!~chs || !~D.chs) return Data(-1, -1);
return Data(val + D.val, chs * D.chs % MOD);
}
}e(0,1);
struct Matrix{
Data a[N][N]; int x,y;
inline Matrix() {x = y = 0;}
inline Matrix(int X, int Y):x(X),y(Y) {}
inline Matrix operator * (const Matrix &M) {
Matrix ret(M.x, y);
for (int i=1;i<=M.x;i++) {
for (int k=1;k<=x;k++) {
for (int j=1;j<=y;j++) {
ret.a[i][j] = ret.a[i][j] + (a[k][j] * M.a[i][k]);
}
}
}
return ret;
}
}tra[32];
class CoinsQuery {
public:
vector<LL> query(vector<int> w, vector<int> v, vector<int> query) {
int m = query.size(), n = w.size();
tra[0].x = tra[0].y = 100;
for (int i=0;i<n;i++) {
tra[0].a[w[i]][1] = tra[0].a[w[i]][1] + Data(v[i], 1);
}
for (int i=2;i<=100;i++) {
tra[0].a[i-1][i] = e;
}
for (int i=1;i<=30;i++) {
tra[i] = tra[i-1] * tra[i-1];
}
vector<LL> ret;
for (int tt=0;tt<m;tt++) {
Matrix ans(100, 1);
ans.a[1][1] = e;
int cur = query[tt];
for (int i=0;cur;cur>>=1,++i) {
if (cur & 1) {
ans = ans * tra[i];
}
}
ret.push_back(ans.a[1][1].val);
ret.push_back(ans.a[1][1].chs);
}
return ret;
}
private:
};
【Tricks】强大的在线解析工具
1. OEIS

这个玩意儿我就不多说了吧?
CF水题必备(逃
2. WolframAlpha

这个东西似乎知道的人也挺多的?
反正就是巨好用,求个倒数啊,化简一个表达式啊都非常方便
3. Desmos
这个东西你可以叫他在线的几何画板,而且感觉功能比几何画板强大
(虽然我自己不会用 QwQ
—————————— UPD 2017.3.23 ——————————
我校高一神犇ksda47832338用Desmos搞了这么一个东西,太强大了 _(:з」∠)_
所有的东西,包括那个火焰都是用函数搞出来的啊!
【OI人生向】Conoha
本来想折腾一下HostUs的来着
然而这货对于支不支持Alipay内部都没有统一 (╯‵□′)╯︵┻━┻
于是还是搞了一个Conoha,虽然巨贵 QwQ
50元一月啊!我的搬瓦工一年才120……..
不过是KVM架构,于是上了bbr
速度还是非常资瓷的,反正Youtube 1080P没问题
下东西用IDM还是随便5M/s
路由测试下来也是直连,没有绕

总之一切都是那么美好!
但就是贵啊 _(:з」∠)_
【OI人生向】net-speeder
话说之前租了个vps,搭了一个vpn
速度很是不错啊,直接连接都能上500ks/s
但最近似乎环太平洋挖矿大队进驻了我的vps的机房?
反正速度跌倒不忍直视,虽然用kcptun要好一点,但kcptun不方便部署到笔记本上QwQ
于是为了满足某人上pinterest的需求,昨日在服务器上部署了net-speeder
主要参考了一下两个博客:
[1]http://www.sheyilin.com/2016/07/net-speeder/
[2]http://www.jianshu.com/p/f136b30ca3ba
实测速度还是会好一点
【Tricks】英文术语
话说,很多数学上的东西,我都不知道英文是什么 QwQ
于是今天查了一查,感觉这里比较全的样子:http://www.aua.com.tw/translations/?t=Mathematics-Glossary&f=en
留在这里,存个档吧!
【Tricks】Linux下进行对拍
明天就wc考试了,于是来复习一下linux下如何对拍
主要有以下几点:
- 每一次给数据生成程序传递随机种子(代替
srand(time(0)))diff -q代替fc- linux下运行程序前面要加
./
于是代码checker长成这样:http://paste.ubuntu.com/23948238/
数据生成程序长成这样:http://paste.ubuntu.com/23948247/
另外,linux的shell里强制结束当前命令的快捷键是C-c
编译命令一般写成这样g++ code.cpp -o code -O2

【Tricks】Voronoi Diagram
前言
不知道 Voronoi图 的同学可以参见:
https://en.wikipedia.org/wiki/Voronoi_diagram
话说 Voronoi图 真是一个特别优雅的东西
性质简直是优美到不行!
还可以来出题:http://poj.org/problem?id=1379
看起来 Voronoi图 真是一个好东西啊!
然而我并不会

正文
今天整理收藏夹,发现了一个埋藏了很久的网页:
http://alexbeutel.com/webgl/voronoi.html
是在线建 Voronoi图 的东西
如果在我有生之年可以学会 Voronoi图 的话
或许会有用吧?

不过没事的时候玩一玩还是挺不错哒!
效果大概如下图:
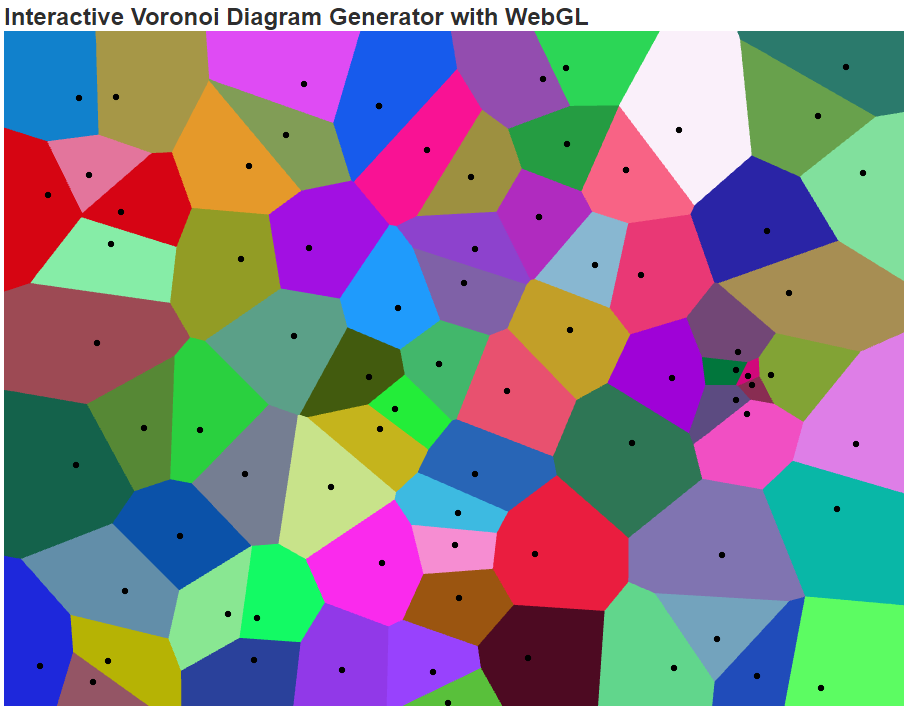
话说这个配色简直跟屎一样啊!
【Tricks】Lambda表达式
前言
很多时候,我们需要定义一些小的函数
比如在sort()时指定比较函数cmp():
sort(a+1, a+1+n, cmp)
bool cmp(const int a, cnost int b) {return a > b;}
但这么小的函数写在外面会有一点不优雅
于是我们可以用 λ表达式 来解决这个问题
解决方案
Lambda表达式如果叫做匿名函数的话可能更能凸显他的特性
详细情况请参阅参考资料中的链接
对于竞赛来讲,似乎Lambda表达式这么用就好:
static auto cmp = [](int a, int b) {return a > b;};
sort(a+1, a+1+n, cmp);
或者再做绝一点:
sort(a+1, a+1+n, [](int a, int b) {return a > b;});
是不是感觉很强 ( •̀ ω •́ )y
兼容性
无论是 Lambda表达式 或是auto都是 C++ 11里的东西
直接交到不支持 C++ 11 的OJ上会CE
于是我们需要加上下面这句指令,以使编译器忽略该错误:
#pragma GCC diagnostic error "-std=c++11"
当然gcc的版本需要在4.7以上,否则编译器根本不知道Lambda表达式是什么 QwQ